

I have a lot of material to cover here, and as is often the case when you have to cover a lot of material in a short time, I will gloss over some details, and maybe even oversimplify, although I will try not to lie outright.
For a long time, people have had machines. They have also had devices that had informational content, and helped calculate, like abacuses:

or old adding machines:

There have also been clever control mechanisms built into other machines, like a thermostat with a bimetallic strip. In such a device, a strip of metal expands or contracts as it gets warm or cool, and you can use this to turn on or off the furnace.
I don't want to get bogged down in the history too much, but I have to drop a few names. Over 200 years ago, a Frenchman named Jacquard invented a loom for weaving intricate patterns in silk. His loom was controlled by cards with holes punched in them, so that the pattern was encoded in the cards. This is a much more sophisticated form of automated control than the simple on/off of the thermostat. In effect, Jacquard's loom was programmable.
A few decades later, in the early 1800's, a man named Charles Babbage collaborated with Ada Lovelace, daughter of the Romantic poet Lord Byron, to create the Analytical Engine, which worked with brass wheels and rods. Today you can build them with Legos or read a comic book about them.

In the 1930's (about a century after Lovelace and Babbage!) things really started to pick up with regard to computers. Several people or teams of people were converging on certain ideas around then. With WWII looming on the horizon, the US government was funding research into computers for potential military use. During this time, there was a definite sense that the goal was a number cruncher, a device that could do a lot of math accurately and quickly. More recently, we have broadened our idea of why you would want a computer in the first place.
This was the age of computers being made of electro-mechanical parts,
with large rooms full of loud whirring and clacking wheels and switches.
Even when computers became fully electronic, we aren't talking about
chips of silicon, but each diode being a vacuum tube, which looks a lot like
a light bulb, and burns out like a light bulb.
There were some people at this time who were thinking deeply about computation, and what a computer could be, and thinking beyond the technical limitations of the day. John von Neumann conceived of a stored-program computer, in which the instructions telling the machine what do to were stored in the same form as the data the machine worked on.
The Imitation Game was a biopic staring Benedict Cumberbach as the British genius Alan Turing, who also conceptualized, in a mathematically formal way, what a computer was, and he explored what it means to compute.
One of the key breakthroughs of this era was what has been called the most influential masters' thesis of all time, published by Claude Shannon in 1938. It had the unassuming title "A Symbolic Analysis of Relay and Switching Circuits". Shannon was a 23 year old at MIT at the time, and he ushered in the digital age by showing how we could make electronic circuits that implemented a form of mathematical logic called Boolean algebra.
digital: from "digit", as in finger. The idea here is that you are counting integers, discreet numbers, as opposed to things that vary on a continuous scale. digital vs. analog. Lots of control mechanisms in the past (and present) are analog, like that bimetallic strip.
You may have heard that computers deal in 1s and 0s. This is true. We count in base 10 (the decimal system) only because of the evolutionary accident that we happen to have ten fingers (digits). Because of this, we came up with a number system with ten distinct symbols (numerals). If we had only eight fingers, we would all be counting and calculating in base eight: 1, 2, 3, 4, 5, 6, 7, 10, 11, 12 . . . At the simplest extreme, we have base 2 (the binary system), with only two digits, 0 and 1: 1, 10, 11, 100, 101, 110, 111, 1000, 1001 . . . Base two would be cumbersome for us to use in everyday situations, but it makes the electrical engineering in computer chips easier if they only have two digits to worry about. You may already know that a Binary digIT is called a "bit".
I ask you to imagine that electrical engineers decide arbitrarily, based on what works best electrically, that, say 5 volts is 1, and 0 volts is 0. Then they can wire up circuits with transistors and diodes that do stuff with these voltage levels that will implement various math/logical functions. It would be much harder to create a digital computer that worked in base 10. You'd have to divide a range of voltages into ten subranges, and have your circuits be able to distinguish them.
Also, base two allows us to apply Boolean logic. Boolean logic was invented in the 1800's by George Boole. He pretty much invented mathematical logic. For thousands of years up to that point, "logic" as something you would study, was thought of as a branch of rhetoric. That is, it was about arguing, verbally, as one might in a debate or a court of law. Boole basically created symbols and functions, and turned it into algebra. Almost a century later, Claude Shannon turned his algebra into circuits.
I am going to introduce, very briefly, the three big Boolean functions, AND, OR, and NOT. If you don't quite get this, that's OK, but you should at least get a taste of it.
AND is a function that produces one bit as output and takes two or more bits as input. AND only produces a one if all of its inputs are one, otherwise it produces a zero. So x AND y AND z is 1 (true) if and only if x is 1 (true), and y is 1 (true), and z is 1 (true).
OR is a function that produces one bit as output and takes two or more bits as input. OR produces a 1 if any of its inputs are 1. In other words, it only produces a 0 if all of its inputs are 0. So x OR y OR z is 1 (true) if x is 1 (true), or y is 1 (true), or z is 1 (true), or any combination of them is 1.
Note that these functions correspond to our English language understanding of the terms "and" and "or". We would say "the sun is hot" and "water is wet" is true, but if one of the statements anded together were false, the whole statement would be false, even if the other one were true: "the sun is hot" and "the moon is made of green cheese". However, we might say that "the sun is hot" or "the moon is made of green cheese" is true.
NOT is a function that produces one bit as output and takes one bit as input. It simply flips, or inverts its input bit. So NOT 1 is 0, and NOT 0 is 1.
We can show exactly how these function behave by writing out truth tables for them, assuming two-input AND and OR.
You can hook these gates together to form complex functions, and do some binary arithmetic, if you interpret 0s and 1s as numbers. As with traditional algebra, these three operations, and the numbers 0 and 1 can be manipulated in lots of ways, and are subject to all kinds of algebraic rules. You perhaps know about things like the commutative property, the associative property, the distributive property. All that stuff applies to Boolean algebra. The main thing for our purposes is that everything I'm going to describe now is made of AND, OR, and NOT, hooked together in complex arrangements.
Just to give you a taste of how this would work, I am going to give a lightning fast run-through of how you might make a circuit that adds two multidigit numbers together.
As in base 10, when we add in base 2 we arrange the digits over each other, and add each column, carrying if necessary. So let's add 13 + 7 to get 20.
| 1 | 1 | 0 | 1 | |
| + | 0 | 1 | 1 | 1 |
Note that for each column, we did basically the same thing, and the only thing that connects the columns is the carry. All we have to do is make a circuit that can do one column, and then we can chain as many of them as we like together, the carry out from one feeding into the carry in to the next. For each column, we take three bits as input: the bit from one number, the corresponding bit from the other number, and the carry in from the last column. For each column we produce two bits as output: the bit for the sum that drops down, and the carry we feed into the next column. This suggests two separate circuits: one to generate the sum bit, and one to generate the carry out bit. Both of these take the three input bits.
The first step in creating the digital circuits to implement our two functions (sum and carry out) is to write a truth table of what we want our circuits to do. Then we worry about creating the circuit to produce outputs to match the rows in the truth table. For each of our functions, there are three input bits. All possible combinations of three bits is 23 = 8, so our truth table has 8 lines in it. We can write the two output bits in separate columns next to each other on the same truth table.
| a | b | carry in (c) | sum | carry out |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
Now we can just read across to derive the Boolean function for, say, the sum circuit. We take note of all the rows in the truth table where the sum is 1, and we make sure our circuit will produce a 1 for those combinations or inputs and only those combinations. That is, we want a 1 when:
And we can now create a circuit from this expression with AND, OR and NOT gates. The corresponding exercise for the carry out function is left as an exercise for the reader.
I once wrote a book about Boolean algebra, its history, and its application to digital circuits. I'm not going to plug it here, and I'm not even going to dwell to much on that aspect of computer architecture. For reasons beyond my control, it is way too expensive anyway.
I am, however, going to plug this book. It is apparently self-published, which is usually the kiss of death, but this one has lots of positive Amazon reviews.
I wish I had this book when I was learning this stuff. My own book is all about Boolean algebra, its history, and how to think about it and use it. This one covers that stuff pretty briefly, and is mostly about how Boolean algebra can be used to build a computer CPU (Central Processing Unit) and memory. In it, the author invents his own toy CPU, and shows how to build it all the way up from just the AND, OR, and NOT gates I just introduced.
Similarly, I also really like this book, which also builds its own simple CPU up from logic gates.
I want to point out that none of these books has anything to do with electricity or electrical engineering. I honestly don't know much about volts, amps, joules, ohms or the rest of that stuff. The books are about the logic gates on up, which in this era happens to be implemented electrically.
The CPU is where the action is, the real brain. Over the years, there have been many different designs of CPU, made by different companies. One of the big breakthroughs in the 1970's was the widespread availability of single-chip CPUs: an entire CPU on one chip of silicon.
Here is the Z80, an immensely popular 8-bit CPU from the late 70's/early 80's:

And here is the Motorola 68000, a 32-bit processor from roughly the same era, but a little later:

Here is an Intel CPU that was released in the early 90's:

Finally, here is a modern Intel CPU:

Each of the legs in the photos is an electrical connection, and each one carries one bit, either in or out of the CPU. The early, more primitive CPUs had fewer, then more as the complexity of the chips increased, along with the size of the data they could handle at any one time. In the lab, you really don't want to bend or break one of those legs off as you are seating the CPU into its socket. Note that the last one didn't have those fragile poky legs, but a huge array of so-called contact pads.
These pictures show what we call "chips", but the actual chip is a square of silicon embedded in a ceramic or plastic package. The chip inside is connected to all the external electrical contacts, the legs or contact pads. The chips are fabricated side by side on round slices of silicon called wafers.

You hear a lot about silicon. It is en element on the periodic table, and is an example of a type of material called "semiconductors". Semiconductors have electrical properties that can be enhanced or modified by introducing slight impurities into them during manufacturing. These properties allow differently modified (or "doped") semiconductors sandwiched together to form transistors.
The individual transistors that make up the logic circuits are built up on the wafer of silicon in layers of pathways and connectors with different electrical and conductive properties. Each layer is laid down through a process called photolithography. You put down a layer of a photosensitive stuff, then project an image onto it of the pattern you want for that layer, using some form of light (perhaps X-rays) shined through a mask. Depending on what kind of photosensitive stuff you laid down, the light will either eat away the photosensitive stuff, exposing the layer below it, or cause the parts of it not to be eaten away. Now you have a stencil made of your photosensitive stuff, and you can use acids to wash away the parts of the layer below, etching a pattern into it, or you can bombard the wafer with high-energy ions that only hit the exposed bits through the stencil, changing the electrical properties of the areas they hit.
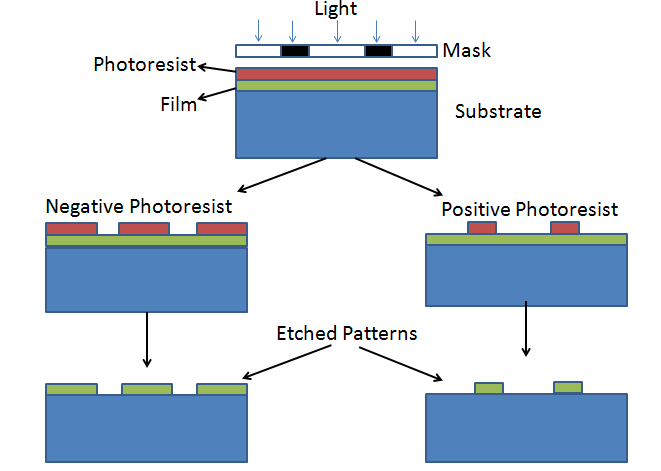
In this way, layer upon layer, you can construct patterns and electrical pathways on the wafer. As time goes on, we have developed ways of making these patterns smaller and smaller, so that we can fit an awful lot of transistors on a chip.
Again, this talk is more about the logical architecture than the physical way it is made, so I won't be talking any more about silicon and fabrication.
Note that I've made the disk and memory separate. I'll get back to this.
Inside the CPU, there are some places to park numbers, called registers. These hold numbers in binary that are as wide as the CPU can handle. Let's say there are 8 of them, numbered 0-7.
The memory, or RAM, can be thought of as a huge list of such slots for numbers, each one with an "address", 0-some huge number. Think of it like a huge chest of drawers, each one numbered, with each drawer capable of holding a single binary number of (usually) 8 bits.
The CPU is connected to the memory with a data bus, an address bus, and a read/write line. The read/write line is a single bit, on or off; 1 means read and 0 means write (or the other way around, as long as both memory and CPU agree). These "buses" are just wide paths of parallel wires that carry individual bits, let's say 32 bits wide. It's simpler if we think of the hypothetical computer we're talking about as a 32 bit machine, so that its registers are all 32 bits, and the address bus is 32 bits wide. Interestingly, most architectures still have each byte (8 bits) in memory individually addressable. So with a 32-bit wide address bus, there can be up to 4Gb of addressable memory.
The CPU can write to a particular address in memory by putting that address on the address bus, putting the value it wants to write on the data bus, and setting the read/write line to "write". Likewise it can read a value from memory by putting the address it wants to read from on the address bus, and setting the read/write line to "read". Then the memory's job is to obey: if the read/write line says "read", put the contents of the desired memory location (read from the address bus) onto the data bus for the CPU to pick up, and if it says "write", put the value it finds on the data bus into the location specified by the address on the address bus.
This kind of memory is called RAM, for Random Access Memory because you can access any memory location at any time just by putting the address location on the address bus. It's not like a tape or something where you have to walk through all the lower addresses to get to the higher ones.
When you have a 32 bit number, say, in a register, you could just use it as a number, and add it to another number. It could represent some textual data, or a color of a pixel or two on a screen. But when it is used as a memory location, it is called a pointer.
Things get even more interesting when you lie to the CPU, and swap out some memory, and stick some I/O device in its place. So the CPU thinks it is reading and writing to RAM, but it is really reading from an input device, like a mouse, a keyboard, or a camera, and writing to some output device like a screen or a printer. For our purposes, a hard disk counts as such an I/O device.
In addition to the 8 general purpose registers I just mentioned, the CPU has a special register, the Instruction Register. It also just holds one number. But the way the CPU is engineered, the number in the instruction register is treated as, you guessed it, an instruction. There is another special register that holds an address, and it is called the Program Counter. It holds the address in RAM of the next instruction to fetch to put in the Instruction Register. The CPU has some fairly simple control circuitry to do the following: fetch the instruction pointed to by the Program Counter into the Instruction Register. Do that instruction. Repeat forever.
Here is the beauty of the so-called von Neumann machine: instructions are in memory, just like data. Infinitely flexible, programmable. So memory has numbers in it, at particular addresses. Some of these numbers may be treated as data, but some may be treated as instructions. Once the CPU demands a number from a memory location be loaded into its IR, it looks at that instruction and does whatever it should for that particular instruction, or opcode.
This idea of having the sequence of instructions live in memory just like data, and take the same form as the data, was a huge breakthrough, and gave us truly general purpose computing. This plasticity and flexibility ushered in a new age, and we see the results around us all the time.
Depending on what kind of CPU it is, what company designed it, each CPU has a specific instruction set. So, for instance, one opcode might mean "add whatever number is in register 3 to whatever is in register 4 and put the result in register 5". Key concept: each instruction is just a number in memory, like the data.
The CPU also has an input - an actual wire leading into it called its clock. This is just a square wave electrical signal, effectively an alternating 0 and 1.
Every tick of the clock, the CPU does something. Next tick, it does something else. So here is all it does, ever. When you first turn the CPU on, it puts 0 into the Program Counter and starts. This causes the CPU to fetch whatever number is at location 0 in RAM, and put that in the Instruction Register, then does that instruction. Then it goes to the next instruction.
Some instructions take up more than one word, for instance, "take the number at location X, multiply it by the number in register 7, and stick the result in location Y", where X and Y are specified right after the instruction itself. In such a case, the instruction would take up three words, and the next instruction would be after that. The CPU knows for each instruction how many words it takes up, and knows to increment the Program Counter by the appropriate amount to point to the next instruction in the sequence.
In addition to this ordinary tinkering with the Program Counter, some instructions tell the CPU to mess with its own instruction flow: instruction 1: "subtract the number at location X from the contents of register 7, put the result in location Y". Instruction 2: "If the result of the previous instruction is negative, jump to the instruction at location Z" where X, Y, and Z are specified right after the instruction itself. To "jump" to a different address than the one it otherwise would have executed, the instruction orders a new value to be loaded into the Program Counter.
So these instructions are pretty primitive, and there is a quite limited number of them, generally. There are instructions burned into the CPU for doing basic math functions on the contents of registers, and locations in RAM, as well as for branching and moving data around between the RAM and the registers. Nevertheless, you can use these primitive instructions to do all kinds of complex things.
I want to emphasize here that when you buy a CPU, it already has the knowledge of how to carry out each instruction in its instruction set. This is part of the design of that particular CPU. It has a particular list of instructions, or opcodes, and it knows how to do each of them. So you take the CPU and wire it up to some RAM, and it is your job, now, to put something in that RAM, like an sequence of instructions that will make the CPU do something useful. This is the job of the programmer. The CPU comes with an instruction set, and you use those instructions to write programs.
In practice, any computer you buy will have RAM, which is blank when you turn on your computer, ready to be written to and read from, and some ROM or Read Only Memory, constituting a boot loader or BIOS (Basic Input/Output System). When the CPU first has power applied to it, it comes to life and may be hardwired to put zero in its Program Counter and start executing. So you better have some memory at location 0 with a program of some sort. So the manufacturers of any given computer will write a simple startup program and burn it into a permanent memory (or semi-permanent so-called flash memory) and wire it to low memory, starting at zero, for the CPU to chew on when it wakes up. This program will then know how to read the operating system from the hard drive and put it or parts of it in RAM.
There is nothing to prevent the computer from going off the rails and trying to execute data, that is, treating numbers in memory as instructions that were not intended as instructions, but are random numbers, or non-instruction data. This can lead to problems very quickly, since most random numbers aren't even valid opcodes for most CPUs.
There was once a CPU that, like all CPUs, had certain combinations of 1s and 0s that constituted valid opcodes, and any other combinations, if fed to the CPU, would do something random, or at least something the engineers didn't specifically intend. Apparently, there was one particular combination of 1s and 0s that would cause all the data paths within the CPU to open up, so everything was flowing everywhere. OK, so that certainly is bad for a running program, and would give you, shall we say, indeterminate results, indeterminate values in your registers, indeterminate addresses on the buses, that sort of thing. But the problem was worse than that. Because of the way the voltages worked, this condition resulted in a lot of voltage on lots of internal connections all at once, causing the CPU to overheat and fry itself. In effect, this was the suicide instruction. If the CPU ever executed it, you had to replace the CPU. It was named the Halt And Catch Fire instruction, and they later named a TV show after it.

This was arguably the first personal computer. It came out in the early 1970's. It had no keyboard, mouse, or even monitor. It had toggle switches, that could be in either of two positions (0 or 1), and some LEDs that could be lit (1) or not (0). In the very old days (and I have personally seen one of these machines) you actually had to program computers with toggle switches: 0s and 1s. You knew the instruction set of the CPU you were dealing with, and toggled into memory the program you wrote, instruction by instruction. This is really tedious.
In order to make this easier, one of the early programs people wrote was an assembler. To understand what an assembler is, I have to go on a detour.
You know that your computer's hard drive has a bunch of files, and these files are organized in folders (sometimes called directories). Sometimes folders are inside of, or under, other folders. Basically, all the folders on your computer are arranged in a tree, with one root folder at the top. You might have files like cat_video.gif, cat_video.mp4, uptown_funk.mp3, term_paper.docx, or birthday_party.jpeg.
This file system is a sort of fiction that is maintained by the computer for your benefit. It is really a kind of database. Don't worry about what that means for now. The important thing is that everything on your computer's hard drive is a file of some sort (or a folder, which itself is a kind of file). Your MP3s that constitute your music collection, your JPEGs that are photos, your Microsoft Word documents - they are all files.
A file is a big stripe of numbers - ones and zeros - laid out on your hard drive. Generally, there is a lot more space on your hard drive than there is in your RAM memory, but it takes much longer to fetch it and copy the contents off the hard drive and into RAM where the CPU can play with them. You might have 8 Gb of RAM, but 500 Gb of hard drive space. So what are these numbers in files? What do they mean and how does the computer know what to do with them?
When you start up Microsoft Word, you click an icon with a big "W" on it, right? What that is actually doing this: that icon tells the computer to go to a certain file on the hard drive, open it, load the first chunk of it into memory, read each byte in it as a CPU instruction, and start executing those instructions. Such a file is called an binary executable.
Binary executables are files that contain actual opcodes for the particular machine's CPU. When the sequence of instructions in the binary executable are loaded into memory and the CPU starts acting on them, they make the computer carry out a particular task, like fire up a browser, or run Microsoft Word. Then, once Word is running, you might direct it to open other files, that contain not binary instructions, but Word documents.
How are these binary executables created? Surely engineers don't just peck in actual binary numbers, constituting machine code instructions. At first, they did exactly that, but soon they came up with a more human-friendly way of expressing to the computer what it should do. And in order to understand that, I have to explain ASCII.
What I am about to explain is an oversimplification, in that I'm ignoring all alphabets but the US Latin one. Basically, what I am about to describe is obsolete, superseded by a scheme called Unicode.
ASCII stands for "American Standard Code for Information Interchange". It is just a simple code for translating binary numbers into letters, numerals, or punctuation marks. 65 means 'A'. 55 means '7'.
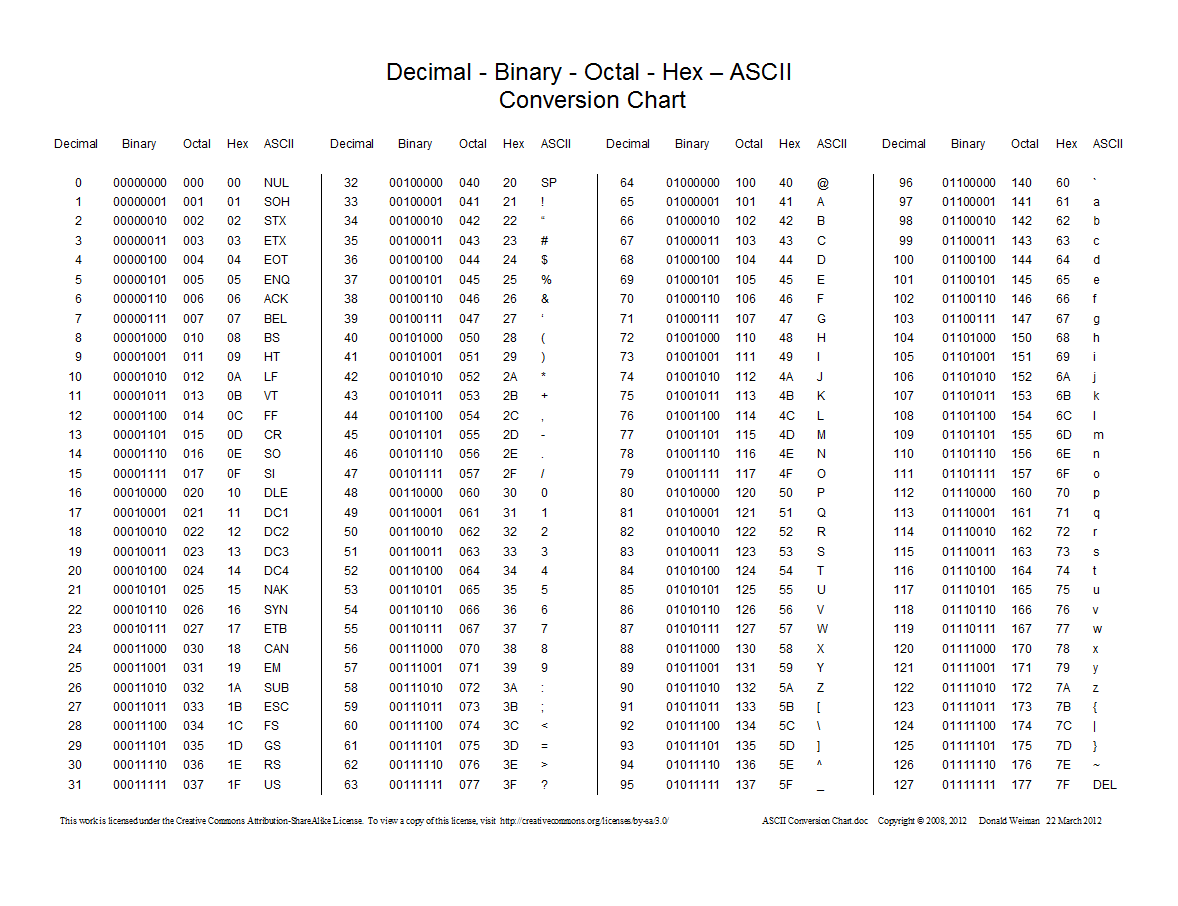
We have 26 lower case letters, 26 upper case letters, 10 numerals, and a bunch of punctuation. You can have 128 different values in 7 bits, so each 8-bit byte can easily store enough information to code for one character. Any time you have a sequence of English text that you want to store in a file, you can encode it in ASCII. Note that there is no information about formatting (other than slapping spaces and tabs in there) or anything about fonts, colors, margins, or any of that other word-processing stuff. Just the so-called raw text itself.
A file with nothing but pure ASCII text in it is, in fact, called a "raw text file", and is usually given a file extension of ".txt". If you create a raw text file containing the single word "hello" in ASCII, it will be six bytes long, one byte for each letter, with byte containing the pattern of 1s and 0s corresponding to the respective letter in the ASCII chart. You can easily create such a file using Notepad or the equivalent program on your computer. You open the program/app, and what you type on the screen gets written to a file in ASCII when you "Save As".
A Microsoft Word document file is not pure, or raw, ASCII. It has a ton of other stuff in there that the engineers at Microsoft decided that Word needs to represent a full, rich document. They invented that file format, and Word knows how to interpret it. A binary executable, as I said before, has machine opcodes in it, and perhaps data the program operates upon. But when you open a file and look at it, it's just a series of binary numbers.
What about the content of the file itself tells you what kind of file it is? Not much, really. You can take an ASCII text file, and open it in Word. Word is smart enough to know all about raw text. You can trick your computer into trying to execute a Word file or a text file as if it were an executable. This "program" will crash immediately, as the computer's CPU runs into nonsense opcodes.
I said earlier that the first executable files had to be punched in opcode by binary opcode somehow, but people quickly figured out a better way of doing it. One of the great things about ASCII is that it is easily machine-readable, and machine parsable. That is, it's pretty easy to create a program that can open an ASCII file, read the contents into RAM, and look for certain patterns of characters. Because the program doing the reading knows that the input file is ASCII, it knows that each byte in the file is a character (letter, numeral, or punctuation mark), and it just scans along looking for certain sequences. If you see one pattern, like "cat", (99, 97, 116) do one thing, but if you see another, like "dog" (100, 111, 103) do something else.
Recall that each type of CPU has its own instruction set, and each binary opcode makes it do something different. One opcode might mean "load a byte of memory from the address specified right after the opcode into register 4", and another might mean "add the contents of register 3 to the contents of register 5 and put the result in register 5". Each opcode is just a number. But we can come up with a little language that is slightly more human-readable with one line of text directly corresponding to one machine opcode:
| operation | encoded in our language |
|---|---|
| load a byte of memory from the address specified right after the opcode into register 4 | "LOD X,04" |
| add the contents of register 3 to the contents of register 5 and put the result in register 5 | "ADD 03,05,05" |
Now it should be pretty easy to craft a program that can open a raw text file containing nothing but lines in our language, and translate each line, one-to-one, into opcodes and write those opcodes into another file. This file will then be an executable. Then you could run this executable just as you would any executable, with the computer opening the file, and reading the contents as opcodes, one by one into the instruction register and executing them. You could write such a program with little more than a simple lookup table. This language is called assembly language and the program that does the translation from assembly language text into binary executable is called an assembler. Somewhat confusingly perhaps, sometimes people refer to assembly language as "assembler" as well.
Clearly you are going to have a much easier time writing assembly language than coding raw 1s and 0s into memory to craft a binary executable. But assembly language still has its problems. First, machine code instructions are quite low-level. Even though we now have a nicer mnemonic way of handling them, it is still tedious. There is a one-to-one relation between lines of assembly code and machine instructions, so assembly certainly doesn't buy you any abstraction beyond the basic CPU instruction set, just a more human-friendly way of dealing with it.
Moreover, each assembly language is tied to a particular CPU architecture. A different CPU with a different instruction set would have a totally different assembly language. If you write a huge program in assembly language for a given CPU, you can't ever run it on a different CPU. You pretty much have to throw it out and start over if you ever want your program to run on a different kind of computer.
Once you have an assembler, where each statement or line of code corresponds to one CPU opcode, the next logical step is to dream up a language whose syntax and design are guided by some more abstract notion of how the language should work. In such a language, one line of code might translate to many individual CPU opcodes. Once you figured out exactly how you wanted your language to work, you could write a program (in assembly language perhaps) that acted like the old assembler, but was more sophisticated. It would open up the ASCII file containing your program in your new language, and it would translate each statement into opcodes for the target CPU, and write just those opcodes into another file, which would, as before, be the raw executable.
Such a program is called a compiler. You are said to compile the ASCII source code to produce the executable file. Note that the compiler, like the assembler, is targeted at a particular CPU architecture, with a particular instruction set. Also, of course, the resulting executable contains opcodes that only work on the particular CPU it was compiled for. The beauty of using such a high level language rather than assembly language (other than the ease of use and comprehensibility of it) is that the source code itself is general. That is, you could take the same source file and compile it for one CPU using one compiler, and a different CPU using a different compiler.
High level languages tend to be a lot more readable by human beings than assembly code. There are some old ones that you may never see in the wild anymore like FORTRAN, COBOL, Basic, and Pascal, and some slightly newer ones that are still in widespread use like C and C++.
Once you have an executable, it is a file full of opcodes. It is very hard to use that to derive anything like the original ASCII source file, or at least in any form that anyone would try to understand. There are such things as reverse compilers, but they are of limited use, really. For example, they can't tell you what any variables or routines were called, so they have to make up nonsense names, and obviously they can't know what comments were in the original source code.
A traditional model for the software industry was for a company to write a bunch of software and keep the source code as a trade secret, and sell CDs (or make available online) just the executable. That way, people could pay for the runable program, but no one but company employees could see or modify the source and recompile it to come up with a new version. Microsoft Word is an example of this sort of thing. Somewhere in servers within the Microsoft corporation there is a bunch of ASCII files that constitute the source code for Word, but what you have on your computer is just the executable: the end result of compiling all that code. You have a file on your hard drive that is just a stripe of machine-readable opcodes for your particular CPU type.
That said, there is a huge amount of software out there that is open source. This is software that is written by people who, for various reasons, put the source code itself up on the internet for anyone to look at, download, modify, and recompile as they see fit. This computer I use here runs an operating system called linux, which itself is open source, as is all the software on it. Some of you may run the Firefox browser - it is open source, as is most of the Chrome browser.
Compiled languages comprise one of the kingdoms of computer languages. The other kingdom is so-called scripted or interpreted languages.
Back before windows and GUIs, you would communicate with your computer through a black and white terminal. It just displayed text. There was a prompt, and effectively a program was just sitting there running, waiting for your input. If you typed a command at the prompt and hit ENTER, this running program, the operating system's interactive command interpreter (sometimes called the shell), would try to execute that command: delete that file, rename that file, run that compiled executable, move to a different directory/folder, print that file, etc.
If there were sequences of commands you entered often, you could open an editor (another compiled executable app) and type the commands in, each on a separate line, and then tell the OS's command interpreter to suck in that file and act on it just as if you had sat there and typed the commands in by hand, one at a time.
Over time, instead of just batching up commands for the particular OS's command interpreter, people started inventing sophisticated languages in their own right that are intended to be interpreted on the fly, at execution time, by an interpreter, and never compiled into a separate file of executable instructions. You eliminate the middleman. In this case, the interpreter is the blob of executable code. The ASCII file of instructions that the interpreter reads and executes is called a script.
Some examples of interpreted languages are JavaScript, python, Perl, and bash. So to write a python script, you open an ASCII editor, type in your python code, and run the python interpreter and suck in your ASCII file.
So with compiled code, you write out an ASCII file of source code, compile it once, then let everyone have the binary executable that they can then run directly on their own computer (e.g. Microsoft Word). But with interpreted code, the script (source code) is what all the users get on their individual computers, and when they want to run the code, they feed the script into an interpreter that is already sitting on their computer.
There is a difference in performance between compiled and interpreted code. When you compile a program, at compile time you translate, once, your ASCII file of human-readable instructions into the machine code instructions that your CPU can operate directly upon. Whenever you execute the program, the computer opens the file, and can immediately run the opcodes in that file.
In contrast, in an interpreted language, the interpreter must run, and it sort of functions as an on-the-fly compiler, translating each line of the script into machine code as it is executed, each time it is executed. For this reason, compiled code generally runs faster than interpreted code. On the other hand, interpreted scripting languages are generally easier to learn and use. Also, they are sort of inherently open source, since there is no separate opaque blob of executable code, other than the interpreter itself. When you write a python script, that's it, right there for the world to see, in all its ASCII glory. The source code is what you ship.